مدت زمان تقریبی مطالعه: 7 دقیقه
19 دی 1400
معرفی خوشه بندی (clustering) و 6 کاربرد آن
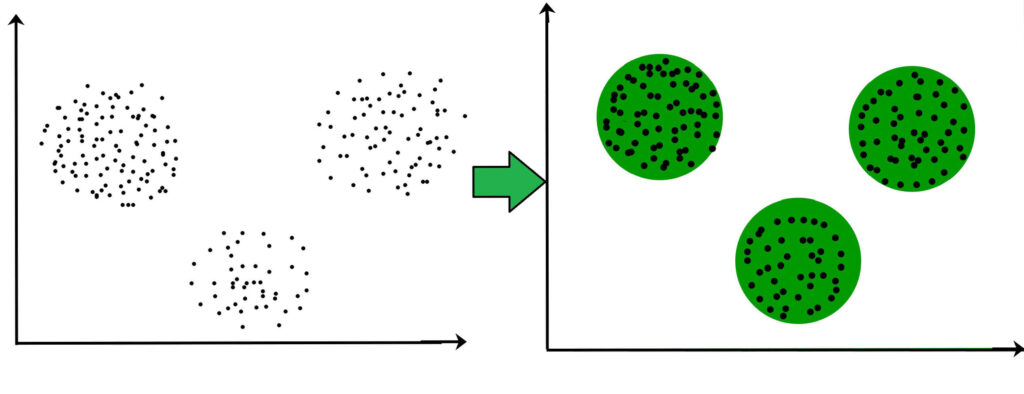
مفهوم کلاسترینگ (Clustering) یا خوشه بندی در داده کاوی به معنای تقسیم دادهها (اشیاء) در گروههایی است که تشابهات بین دادهها داخل هر دسته، نسبت به دسته یا گروه های دیگر بیشتر است؛ به هر گروه یک کلاستر گفته میشود. بنابراین در خوشه بندی، گروهی از اشیاء طبق تشابه و یا عدم تشابهی که نسبت به یکدیگر دارند گروه بندی میشوند. برای مثال دادهها در نمودار زیر که با هم خوشه بندی شدهاند را مشاهده کنید، همانطور که میبینید 3 خوشه وجود دارد.
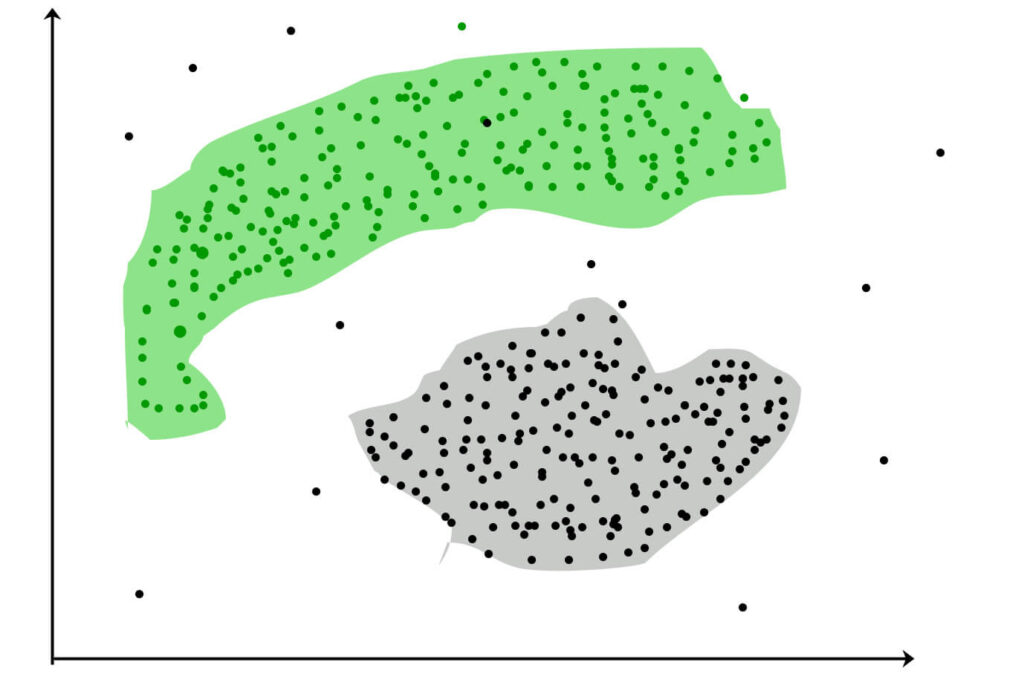
اما در عین حال لزومی هم ندارد که خوشهها دارای شکل خاصی (مانند مثال بالا ) باشند. مثلا به تصویر زیر نگاه کنید که خوشه ها شکل های نامرتبی دارند.
انواع خوشه بندی (Clustering) چیست؟
- Hard Clustering:
دادهها در این مدل میتوانند به صورت کامل داخل یک خوشه باشند یا خیر و حالتی بین این دو وجود ندارد. - Soft Clustering:
به جای قرار گرفتن هر داده در یک کلاستر به صورت مجزا، احتمال وجود آن داده در خوشه ها، به آن اختصاص داده می شود.
الگوریتم های مختلف Clustering
الگوریتمهای مختلف کلاسترینگ، متد های تجزیه و تحلیل دادهها هستند که برای گروهبندی داده های مشابه و الگوها استفاده میشوند. این الگوریتمها سعی میکنند داده های مشابه را در یک گروه قرار داده و داده های متفاوت و مختلف را از یکدیگر جدا کنند. در ادامه، تعدادی از الگوریتمهای معروف کلاسترینگ را معرفی میکنم:
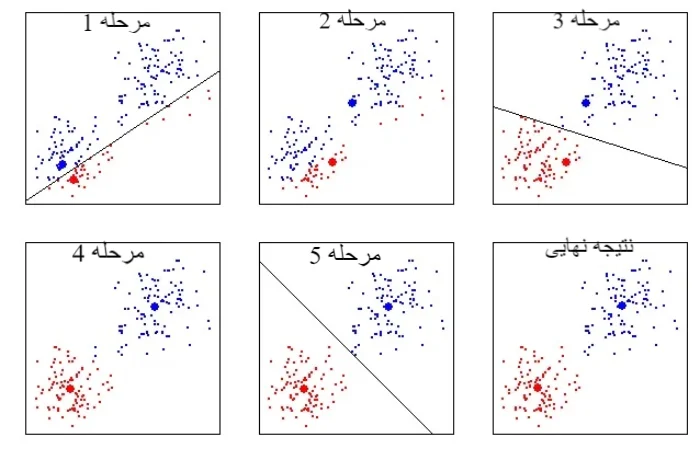
الگوریتم K-Means:
این الگوریتم یکی از محبوبترین الگوریتمهای کلاسترینگ است. با استفاده از این الگوریتم، دادهها به تعداد K خوشه تقسیم میشوند. هدف این الگوریتم یافتن ماکزیمم محلی در هر تکرار است. این الگوریتم در این 5 مرحله کار می کند:
- تعداد دلخواه خوشه های K را مشخص کنید.
- به طور تصادفی هر نقطه داده را به یک خوشه اختصاص دهید.
- مرکز خوشه ها را محاسبه کنید.
- دوباره هر نقطه را به نزدیکترین مرکز خوشه اختصاص دهید.
- مرحله 3 را مجددا تکرار کنید.
پس از پایان، مراحل 4 و 5 آنقدر تکرار می شوند تا خوشه بندی به صورت کامل انجام شود.
الگوریتم Hierarchical Clustering:
خوشه بندی سلسله مراتبی (Hierarchical) همانطور که از نام آن پیداست، الگوریتمی است که سلسله مراتبی از خوشه ها را ایجاد می کند. این الگوریتم با تمام داده های اختصاص داده شده به خوشه شروع می شود. سپس دو خوشه که نزدیکترین خوشه ها به هم هستند، در یک خوشه ادغام می شوند. در پایان، این الگوریتم زمانی پایان می یابد که تنها یک خوشه باقی مانده باشد.
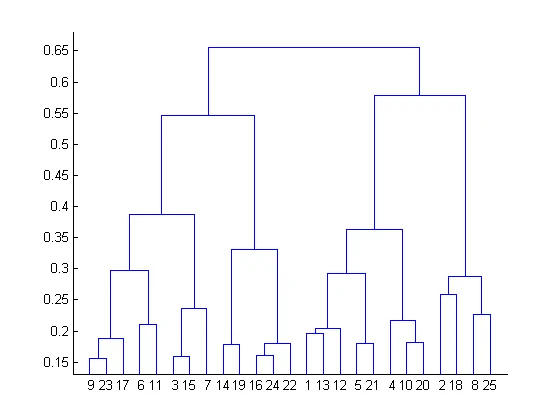
الگوریتم Agglomerative Clustering:
این الگوریتم به صورت رتبه بندی از پایین به بالا، خوشه ها را تشکیل میدهد. در ابتدا هر داده به یک خوشه جداگانه تعلق دارد و سپس کلاسترها با هم ادغام میشوند. این الگوریتم یکی از زیرمجموعه های الگوریتم سلسله مراتبی است.
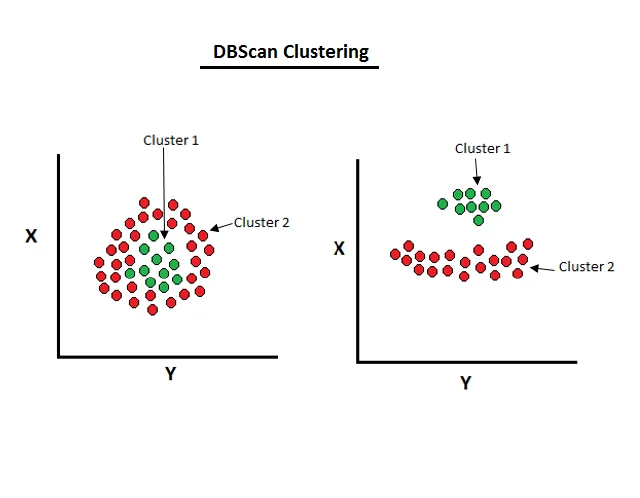
الگوریتم DBSCAN :
DBSCAN که مخفف Density-Based Spatial Clustering of Applications with Noise است، یک الگوریتم معروف در حوزه کلاسترینگ دادهها است. این الگوریتم به وسیله تراکم نقاط در فضای دادهها، خوشه ها را خوشه بندی میکند و قادر به شناسایی نویز و نقاط انفرادی هم میباشد. مزیت اصلی DBSCAN نسبت به الگوریتمهای دیگر کلاسترینگ، این است که نیازی به تعیین تعداد کلاسترها ندارد و به طور خودکار از توزیع تراکم نقاط برای تشکیل کلاسترها استفاده میکند.
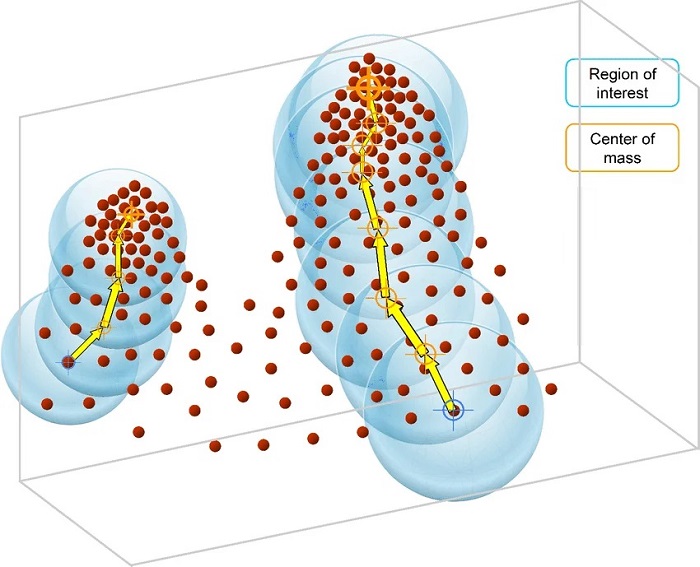
الگوریتم Mean Shift:
این الگوریتم با استفاده از انتقال متوسط نقاط، تلاش میکند بهترین موقعیت برای مرکز هر خوشه را پیدا کند. این الگوریتم بدون نیاز به تعداد کلاسترها، کار خود را انجام می دهد.
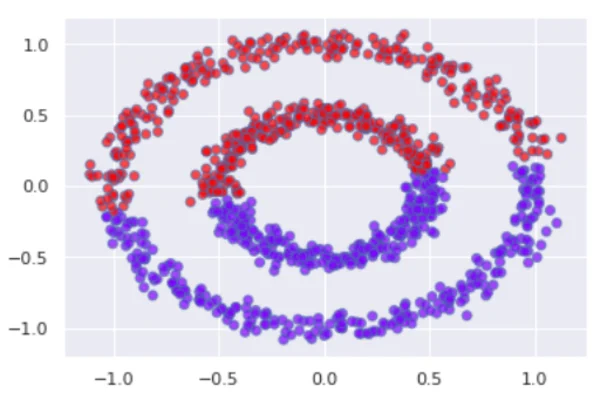
الگوریتم Spectral Clustering:
این الگوریتم از تجزیه و تحلیل ماتریسهای گراف برای کلاسترینگ استفاده میکند. این روش به خصوص برای دادههایی که توزیع نقاط آنها پیچیده است مناسب است.
همه این الگوریتمها برای گروهبندی و تقسیم بندی دادهها به خوشه های مشابه از نظر ویژگیهای مشابه کاربرد دارند و در تجزیه و تحلیل دادهها و شناسایی الگوهای مختلف به کار میروند. هر کدام از این الگوریتمها، ویژگیها و محدودیتهای خود را دارند که بسته به نوع دادهها و مسئله مورد نظر، انتخاب میشوند.
Clustering در یادگیری ماشین و هوش مصنوعی چیست؟
یکی از روشهای یادگیری ماشین(machine learning)، روش یادگیری بدون ناظر یا بدون نظارت است. این روش، به این صورت است که مجموعهای از دادههای فاقد برچسب، خوشه بندی و تجزیه و تحلیل میشوند. در این روش انسان به عنوان ناظر دخالتی ندارد و الگوهای پنهان به واسطهی گروههای موجود در دادهها کشف میشوند. به طور کلی، از این روش به عنوان فرآیندی برای پیدا کردن ساختار معنادار، توجیه فرآیندهای زیرساختی و گروه بندیهای ذاتی در مجموعهای از نمونهها استفاده میشود.
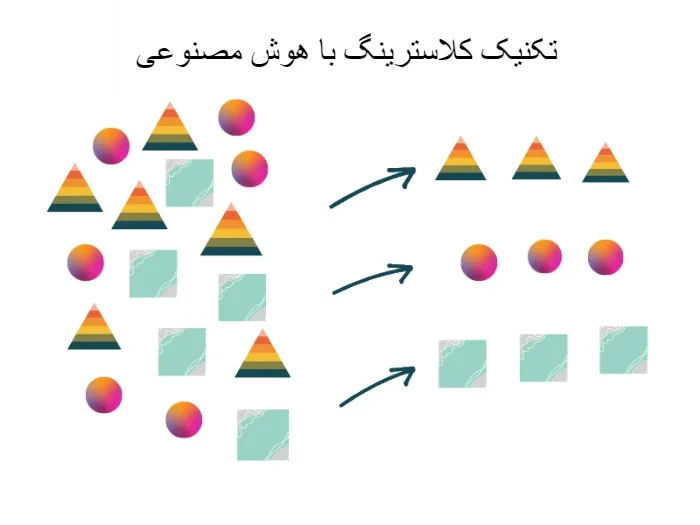
چرا از خوشه بندی (Clustering) استفاده کنیم؟
کلاسترینگ یک تکنیک مهم در داده کاوی و تحلیل دادهها است که کاربرد ها و مزایای زیادی دارد. در ادامه به تعدادی از مزایای مهم کلاسترینگ اشاره شده است:
- شناسایی الگوها و روابط:
کلاسترینگ کمک میکند تا الگوها و روابط نهفته در دادهها را شناسایی کنیم. با تقسیم دادهها به گروههای مشابه، میتوانیم ویژگیهای مشابه در دادهها را شناسایی کنیم. - تقسیم بندی دادهها:
خوشه بندی این امکان را میدهد که دادهها را به گروههای جداگانه تقسیم کنیم. این کار میتواند در تجزیه و تحلیل دقیقتر و مدیریت بهتر دادهها کمک کند. - تحلیل بازار و مشتریان:
در حوزه تجارت و بازاریابی، کلاسترینگ به ما امکان میدهد مشتریان را بر اساس ترجیحات و نیازهای مشابه گروهبندی کنیم. این کار به ایجاد استراتژیهای بازاریابی هدفمند کمک میکند. - پردازش زبان طبیعی:
در پردازش زبان طبیعی، کلاسترینگ به ما کمک میکند کلمات یا جملات مشابه را در یک گروه قرار دهیم و اطلاعات معنایی و مفهومی از متنها استخراج کنیم. - کاهش پیچیدگی محاسباتی:
با تقسیم دادهها به خوشه های کوچکتر، پیچیدگی محاسباتی کاهش مییابد و تجزیه و تحلیل دادهها سادهتر میشود. - استخراج اطلاعات مفید:
با کمک خوشه بندی، میتوانیم اطلاعات مفیدی از دادهها استخراج کنیم که در تصمیمگیریها و برنامهریزیها موثر باشد. - شناسایی نویز و دادههای انفرادی:
کلاسترینگ قادر است دادههای نویز و دادههای انفرادی را شناسایی کند و از آنها در تجزیه و تحلیل دادهها صرف نظر کند.
با توجه به این مزایا، کلاسترینگ بهعنوان ابزاری قدرتمند برای تجزیه و تحلیل دادهها و شناسایی الگوها در حوزههای مختلف مورد استفاده قرار میگیرد.
توجه کنید، هیچ معیاری برای الگوریتم کلاسترینگ خوب یا بد وجود ندارد و معیار اصلی شما برای انتخاب این است که چه ملاک هایی باید به کار گرفته شود و نیاز ما را برآورده کند.
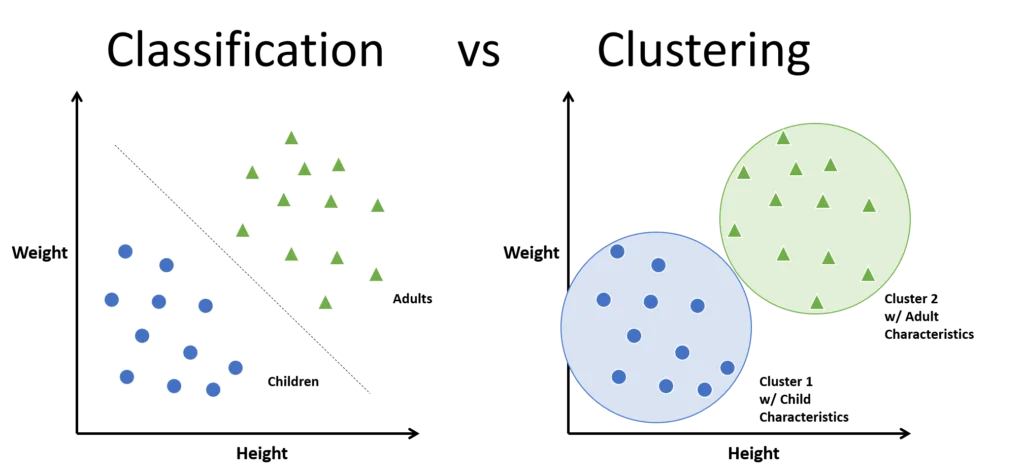
تفاوت clustering و classification در چیست؟
تفاوت clustering و classification در این است که classification یا دسته بندی برای ساخت یک مدل به کار برده میشود تا امکان پیش بینی یک داده جدید، ممکن شود؛ اما در خوشه بندی داده ها به زیر مجموعه هایی تقسیم میشوند که شباهت بیشتری به هم دارند. خوشه بندی مخصوص یادگیری بدون ناظر و دسته بندی (classification) برای یادگیری با ناظر مناسب است. در تعلیم بدون ناظر، داده ها از قبل بدون برچسب هستند؛ درحالی که در یادگیری با ناظر، این قضیه کاملا متفاوت است.
کاربردهای Clustering در زمینههای مختلف
- بازاریابی: میتوان از Clustering برای اهداف بازاریابی استفاده کرد.
- زیست شناسی: برای طبقه بندی گونههای مختلف گیاهی و جانوری
- کتابخانهها: خوشه بندی کتابهای مختلف بر اساس موضوعات
- بیمه: شناسایی مشتریان، سیاستهای آنها و شناسایی کلاهبرداریها
- برنامه ریزی شهری: گروه بندی خانهها و بررسی ارزش آنها بر اساس موقعیت جغرافیایی و سایر عوامل
- مطالعات زلزله: بررسی و تعیین مناطق زلزله زده برای اجتناب از سکونت در نزدیک آن مناطق، جهت کاهش ریسک تلفات ناشی از زلزله.
بیشتر بخوانید:
کاربرد هوش مصنوعی در تصمیم گیری های مدیریتی
پیاده سازی فرآیندهای سازمانی و ۷ مرحله اصلی آن
هوش مصنوعی و بیش از ۱۰ کاربرد آن
سخن آخر
خوشه بندی به عنوان یک تکنیک مهم در داده کاوی شناخته می شود و با پیشرفت تکنولوژی های نو، نیاز به کلاسترینگ روز به روز بیشتر می شود. کاربردهای گستردهی Clustering برای گروه بندی کردن دادهها به عنوان راهکاری برای پیدا کردن ساختار معنادار در یادگیری ماشین و هوش مصنوعی محسوب می شود.
سوالات متداول:
خوشه بندی در داده کاوی چیست؟
به معنای تقسیم دادهها (اشیاء) در گروههایی است که تشابهات بین دادهها داخل هر دسته، نسبت به دسته یا گروه های دیگر بیشتر است که به هر گروه یک خوشه گفته میشود.
خوشه بندی سلسله مراتبی چیست؟
خوشه بندی سلسله مراتبی، همانطور که از نام آن پیداست، الگوریتمی است که سلسله مراتبی از خوشه ها را ایجاد می کند. این الگوریتم با تمام داده های اختصاص داده شده به خوشه شروع می شود. سپس دو خوشه که نزدیکترین خوشه ها به هم هستند، در یک خوشه ادغام می شوند.